

This is part 3 of a series of blog posts originally published on my personal blog. Begin the journey with part 1 and part 2.
We can store vectors in Arroy and efficiently compute the search tree nodes, but we still need some features to make it usable in Meilisearch. Our full-text search engine has great support for filtering; selecting subsets of documents is an essential feature to support. For instance, one of our biggest clients requires the ability to filter through over 100 million YouTube video metadata and their associated image embeddings to effectively select videos released within specific time frames, such as a single day or week. This represents the scalability and responsiveness challenges we aim to address with our filtering system, making it a perfect use case to tailor our developments.
Meilisearch supports the following operators on the filterable attributes of your documents: <, <=, =, != >=, and >. Internally, we extensively use RoaringBitmaps, which are well-optimized sets of integers that support fast binary operations like unions and intersections. When the engine receives a user request with filters, it first computes the subset of documents from the filter that will be inputted into the search algorithms, the one that ranks documents by quality. This subset is represented by a RoaringBitmap.
How was it working before Arroy?
Ranking only the subset of filtered documents has been working well since 2018, but now that we have a new data structure to search on, we need to look at how to implement it. The engine had already supported the vector store feature for months but was inefficient. We were using an in-memory HNSW and were deserializing the whole data structure in memory, searching for the nearest neighbors of the target vector, which was returning an iterator.
fn vector_store(db: Database, subset: &RoaringBitmap, target_vec: &[f32]) -> Vec<DocumentID> {
// This takes a lot of time and memory.
let hnsw = db.deserialize_hnsw();
let mut output = Vec::new();
for (vec_id, vec, dist) in hnsw.nearest_neighbors(target_vec) {
let doc_id = db.document_associated_to_vec(vec_id).unwrap();
if !output.contains(&doc_id) {
output.push(doc_id);
if output.len() == 20 { break }
}
}
output
}You may wonder why we are retrieving the document ID associated with the vector ID. Meilisearch supports multiple vectors by document since the beginning of the vector store feature. This is unfortunate because we must look up every vector we are iterating. We need to maintain this lookup table. The iterator can iterate on the whole vector dataset if the subset is small enough, e.g., document.user_id = 32. We want the document operations to be atomic and consistent, so we have to store the HNSW on disk and avoid having to maintain synchronization between the LMDB transactions and this vector store data structure. Ho! And the library doesn't support incremental insertion. We must reconstruct the HNSW in memory from scratch every time we insert a single vector.
Integrating Arroy in Meilisearch
As we worked on updating Meilisearch to include the new vector store, arroy, we tried out mob programming for the first time. This is where we all code together at the same time. It might sound like it would slow us down, but it actually made us super productive! By tackling problems together right as they came up, we got arroy fitted into Meilisearch much faster than if we'd worked alone.
Arroy is different because it doesn’t return an iterator to give back search results. Now, our search engine is smarter and can figure out the exact number of results it needs to give back, even when there are filters to consider. This teamwork improved our search tool and showed us that working together is key when facing big tech challenges.
Filtering while searching in Arroy
You can find a description of the arroy internal data structure in part 1 of this series. Here is a list of the different kinds of nodes you can find:
- The item nodes. The original vectors that the user provides. The small points on the left.
- The normal nodes, also called split planes. They represent hyperplanes that split subsets of item nodes in half.
- The descendant nodes. They are the tree leaves composed of the item IDs you'll find if you follow a certain normal node path.
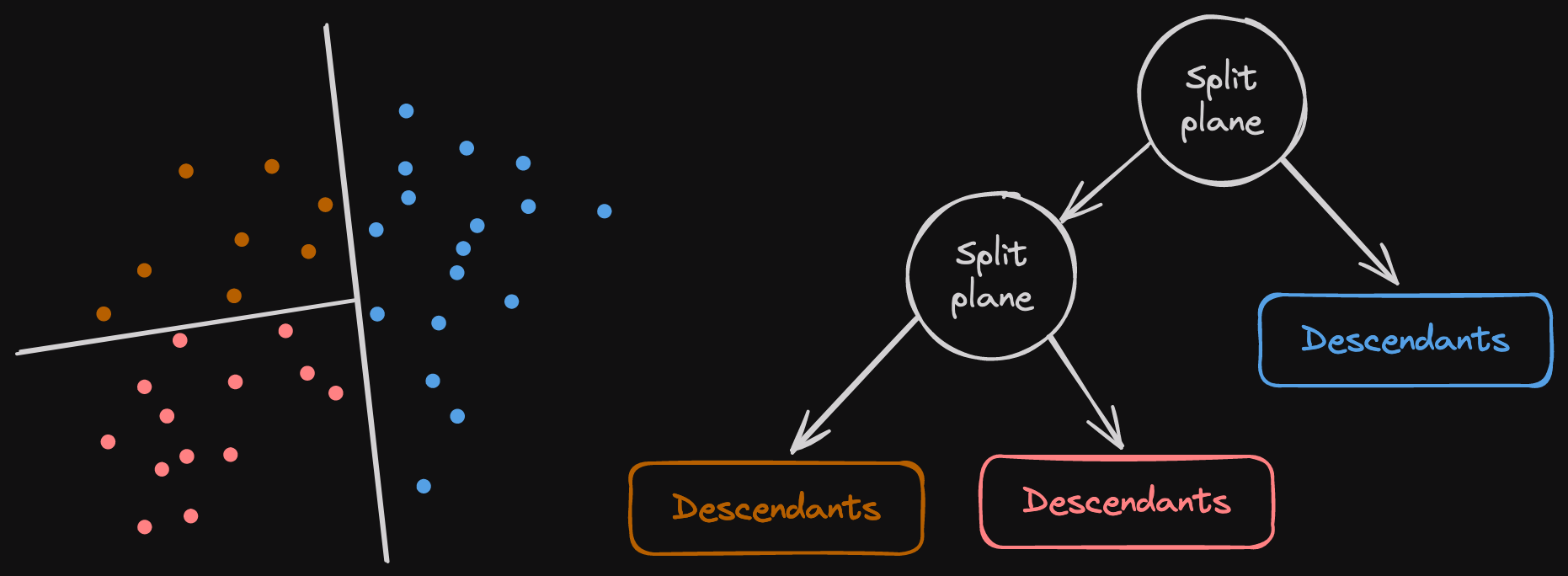
A typical search will load all the normal nodes in a binary heap associated with an infinite distance. Remember that there are a lot of randomly generated trees, and there are, therefore, a lot of entry points. Ascending distances order the binary heap; the shortest nodes found will be popped first.
In the search algorithm, we pop the nearest item from this heap. If it's a normal node, we fetch the left and right sides of the hyperplane:
- If we find normal nodes again, we associate the distance from the hyperplane with positive and negative distances from the targeted/queried vector.
- If we find descendant nodes, we do not push them into the queue but rather directly add them to the potential output list as they represent the nearest vectors we have found.
You probably noticed where I want to go, but this is where magic happens. We modified arroy to store the list of descendants in RoaringBitmaps instead of a raw list of integers. This is another improvement compared to the original Spotify library, as those lists weigh less. Doing an intersection with the filtered subset is way easier now.
However, there is always an issue: the vector IDs are not the document IDs, and Meilisearch, after executing the filters, only knows about the documents. Iterating on the lookup table, I talked about before, constructing the final bitmap with all the vector IDs corresponding to the filtered documents would not be efficient when many documents are part of this subset, e.g., document.user_id != 32. I do not recommend using an O(n) algorithm in the search functions.
Using multiple indexes for efficient filtering
Fortunately, we developed a fun feature that wasn't meant to be used that way in arroy: the support for multiple indexes in a single LMDB database. We originally developed the multiple indexes feature to be able only to open a single LMDB database to store different vector types. Yes! In Meilisearch v1.6, you can describe the different embedders that live in a single index. You can identify the different vectors with different numbers of dimensions and distance functions you can store in a single document. Defining multiple vectors for a single document associated with the same embedder is also possible.
The indexes are identified by an u16. This feature can trick the algorithm into being even more efficient than the previous HNSW solution. Using one store by embedder and vector in a document is interesting because we can now identify the vectors using the document ID. No more lookup database and vector IDs. The vector IDs are reduced to the document IDs. We can use the output of the filters to filter the arroy indexes.
The search algorithm is different on the Meilisearch side. We request the nearest neighbors in every arroy index, sort the results by document ID to be able to deduplicate them and not return the same document multiple times, sort them again by distance, and then return only the top twenty documents. It may seem complex, but we are talking about twenty documents by the number of vectors for a single document. Usually, users will have a single vector.
fn vector_search(
rtxn: &RoTxn,
database: Database,
embedder_index: u8,
limit: usize,
candidates: &RoaringBitmap,
target_vector: &[f32],
) -> Vec<(DocumentId, f32)> {
// The index represents the embedder index shifted and
// is later combined with the arroy index. There is an arroy
// index by vector for a single embedded in a document.
let index = (embedder_index as u16) << 8;
let readers: Vec<_> = (0..=u8::MAX)
.map(|k| index | (k as u16))
.map_while(|index| arroy::Reader::open(rtxn, index, database).unwrap())
.collect();
let mut results = Vec::new();
for reader in &readers {
let nns = reader.nns_by_vector(rtxn, target_vector, limit, None, Some(candidates)).unwrap();
results.extend(nns_by_vector);
}
// Documents can have multiple vectors. We store the different vectors
// into different arroy indexes, we must make sure we don't find the nearest neighbors
// vectors that correspond to the same document.
results.sort_unstable_by_key(|(doc_id, _)| doc_id);
results.dedup_by_key(|(doc_id, _)| doc_id);
// Sort back the documents by distance
results.sort_unstable_by_key(|(_, distance)| distance);
results
}The design philosophy behind these improvements
We're trying to make Meilisearch flexible enough for everyone's needs. Whether your documents are powered by a single embedding, like the kind OpenAI's nifty tools generate, or mixing it up with text and image embeddings, as many e-commerce sites do, we want your search experience to be seamless. We haven't forgotten you for the power users working with multiple embeddings from multi-modal embedders. Our latest improvements ensure that everyone gets to update and fine-tune their search indexes incrementally, making the whole process as smooth as butter.
Big thanks to everyone: Wrapping this up, a huge shout-out to the squad – @dureuill, @irevoire, and @ManyTheFish – for their genius and grunt work that brought our ideas to life. And watch out for @irevoire's upcoming article, where he'll explain how we've implemented incremental indexing in Arroy—meaning you can add new vectors without rebuilding everything from scratch. More on that soon!
You can comment about this article on Lobste.rs, Hacker News, the Rust Subreddit, or X (formerly Twitter).
Meilisearch is an open-source search engine that not only provides state-of-the-art experiences for end users but also a simple and intuitive developer experience.
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking out the roadmap and participating in product discussions.