

What is bucket sort?
Bucket sort is a sorting algorithm that distributes elements from an array into several buckets. Once divided, each bucket is sorted individually, either using a different sorting algorithm or by applying the bucket sort method itself.
What is recursive bucket sorting?
Recursive bucket sort is a specific application of the bucket sort algorithm, where the bucket sort algorithm is used to sort the individual buckets. It is named "recursive" because the same method is used repeatedly to sort sub-buckets until the entire array is sorted.
What is bucket sorting used for?
Bucket sort is used for efficiently organizing data. By distributing the data into different buckets, it makes the later stages of sorting more efficient. It also allows to use different sorting algorithms within individual buckets. This flexibility allows for potential optimizations and makes bucket sort adaptable to various scenarios and data distributions.
What is the best and worst-case of bucket sort?
Bucket sort's performance varies greatly, with the best and worst cases depending on factors such as data distribution, size, and the choice of sorting algorithm used within individual buckets.
The best case of bucket sort
The best case for bucket sort happens when the data is spread evenly across the buckets. This uniform distribution minimizes the complexity of sorting each bucket, leading to an overall time complexity of O(n+k), where n represents the number of elements and k refers to the number of buckets.
The worst case of bucket sort
The worst case for bucket sort arises when all the elements end up in a single bucket, losing the advantage of distributing them across multiple buckets. This scenario leads to a time complexity determined by the sorting algorithm used for that single bucket. It can result in a worst-case time complexity of O(n2), depending on the algorithm.
How does a bucket sort algorithm work?
To better illustrate how it works, let's take the example of Meilisearch. Meilisearch is a search engine that uses bucket sort to sort search results on a set of consecutive rules called ranking rules.
For example, the words ranking rule sorts documents based on the number of words from the query found in the document.
Given the query “Badman dark knight returns”, the words rule will sort the returned documents into 4 buckets. These range from documents that contain all the words (possibly with a typo) to those that only contain the word “Badman”.
If words is the last ranking rule, or if the buckets only contain one document, then Meilisearch returns the buckets from the “best” (matching all words) to the “worst” (matching only one word). Documents matching 0 words are never returned as they have 0 relevancy to the search query.
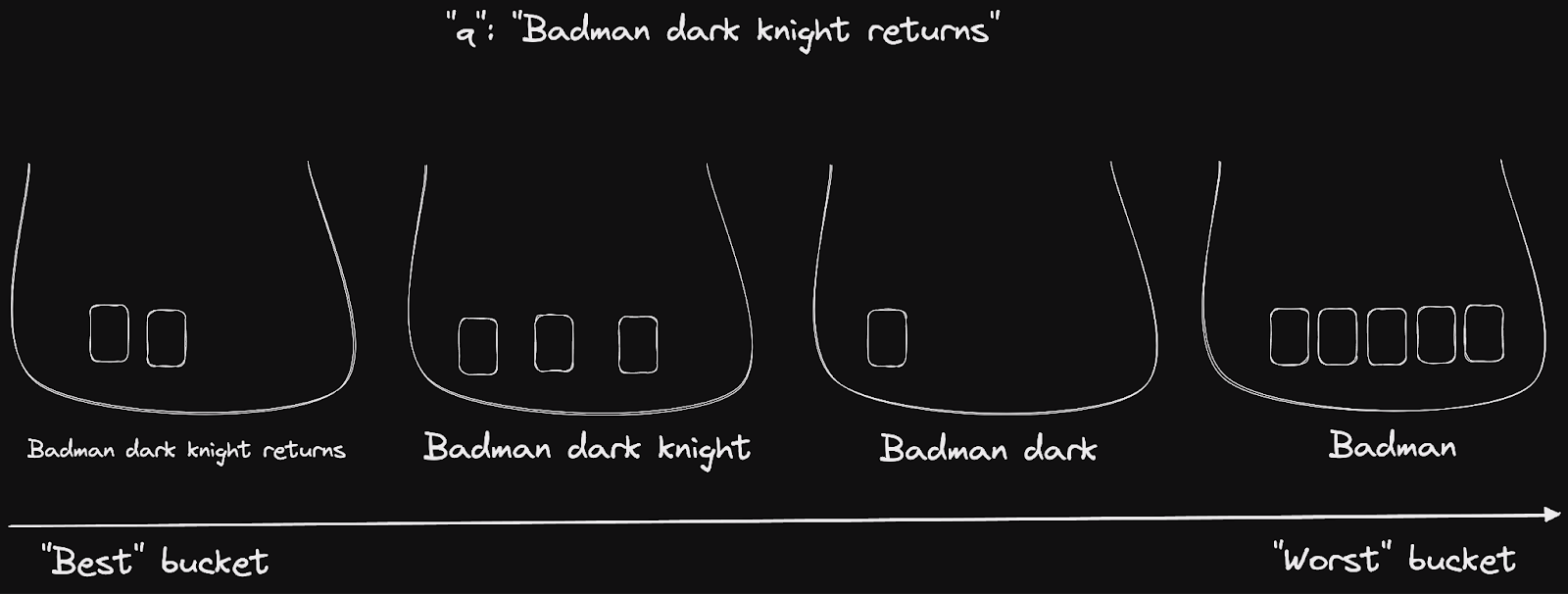
Sorting documents using only a single ranking rule would force Meilisearch to either have a very complicated ranking rule or to perform a simplistic ranking. Meilisearch uses multiple ranking rules sequentially.
If a bucket from the first ranking rule contains multiple documents, the second ranking rule is used on that bucket to “break the tie” between documents. This technique could qualify as “recursive bucket sorting”. The sorting finishes when all the “innermost” buckets contain a single document, or after applying the last ranking rule.
How does a recursive bucket sort algorithm work?
To illustrate recursive bucket sorting, let’s imagine that we now added the typo ranking rule after the words ranking rule from the previous example. The typo ranking rule differentiates between documents that match the query directly and documents that would match if we were correcting one or two typos in the query. The former are better ranked than the latter.
Continuing with our sample query “Badman dark knight returns”, the typo ranking rule helps us further differentiate between documents from the last bucket. Note that it has no effect on the three other buckets, because they only contain documents such that the query has the typo “Badman -> Batman”.
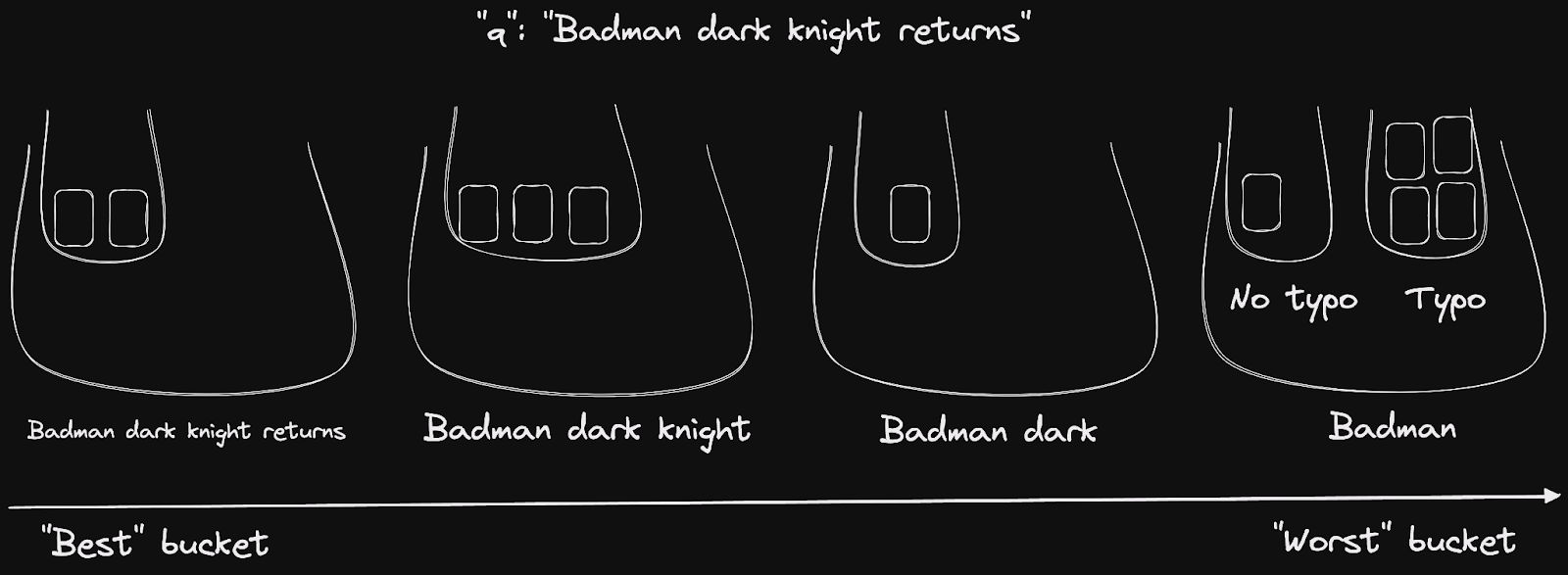
By applying recursive bucket sorting to our query on the sample movies.json dataset, Meilisearch returns the ranking below. For simplicity, we have configured the dataset so that only `title` is a searchable attribute, which makes the results easier to grasp.
| Rank | Query words | Typo correction | Resulting documents |
|---|---|---|---|
| 1 | "Badman dark knight returns" | "badman" → "batman" | Batman: The Dark Knight Returns, Part 1 Batman: The Dark Knight Returns, Part 2 |
| 2 | "Badman dark knight" | "badman" → "batman" | Batman Unmasked: The Psychology of the Dark Knight Legends of the Dark Knight: The History of Batman |
| 3 | "Badman" | No typo | Angel and the Badman |
| 4 | "Badman" | "badman" → "batman" | Batman: Year One Batman: Under the Red Hood |
If you want to try it yourself, you can create an account on Meilisearch Cloud and easily add and set up the movies dataset used to illustrate bucket sort. You can start searching in just a few minutes! Alternatively, you can use our open-source version and run Meilisearch locally. You just need to follow the instructions of our quick start guide.
Conclusion
Bucket sort is a powerful and flexible algorithm, but its workings can be complex to understand without a concrete example. We hope this article has helped you gain a better understanding of what bucket sort is and how it functions.
Meilisearch is an open-source search engine that not only provides state-of-the-art experiences for end users but also a simple and intuitive developer experience.
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking out the roadmap and participating in product discussions.